42nd Annual Meeting of The Royal College of Physicians of Thailand
Dusit Thani Pattaya, Chonburi, Thailand
Mar 20, 2026
I had the opportunity to speak at the 42nd Annual Meeting of the The Royal College of Physicians of Thailand (RCPT) held in Pattaya, Thailand. My presentation focused on the associations between PM2.5 exposure and dementia, in collaboration with the Dementia Association of Thailand.
The initiative itself was led by the The Royal College of Physicians of Thailand (RCPT) to investigate the relationship between PM2.5 and broader air quality indicators, in response to growing concerns about air pollution in Thailand. Participating institutions were granted access to anonymized administrative data from the National Health Security Office (NHSO), enabling large-scale real-world data analysis.

Having previously worked with electronic health records, I was already familiar with issues such as fragmented data silos and inconsistencies across systems. However, this dataset presented a different kind of challenge: it was less fragmented at the system level, but far more complex at scale.
The first major challenge was data quality: specifically, inconsistencies in ICD coding. The dataset originates from the Universal Coverage Scheme (UCS), which ccaptures diagnoses, procedures, and medication records for each patient visit across a large proportion of the population. In practice, coding varies across institutions and over time. The use of dedicated coding staff, who may not have formal clinical training, introduces variability even within the same institution. In addition, clinicians may not consistently record comorbidities that are not directly relevant to the presenting complaint, leading to underreporting of underlying conditions.
These issues are not new, but at this scale they become significantly harder to manage. What might be a minor inconsistency in a single-institution dataset can propagate into systematic bias when working with nationwide administrative data.

The second challenge was computational. The data spans more than a decade of patient encounters, with varying levels of relevancy for the research question. The data is organized at the visit level, with prescriptions recorded in a one-to-many relationship per visit. This required explicit linkage between visit and prescription layers, followed by temporal aggregation into patient-level longitudinal records. Constructing a cohort was therefore not a simple filtering step, but an iterative process of restructuring the data into a format suitable for time-to-event analysis.
The scale of the dataset further compounded this challenge. The national claims data spans multiple fiscal years, with individual data layers reaching tens to hundreds of gigabytes and a total volume in the terabyte range. The dataset included over 12.7 million patients and approximately 74 million person-years of observation. This is substantially larger than the datasets I had previously worked with, which contains 300 thousands at the maximum for Hypertension Data Warehouse . As a result, workflows that were previously feasible on a single machine became impractical due to both memory constraints and processing time.
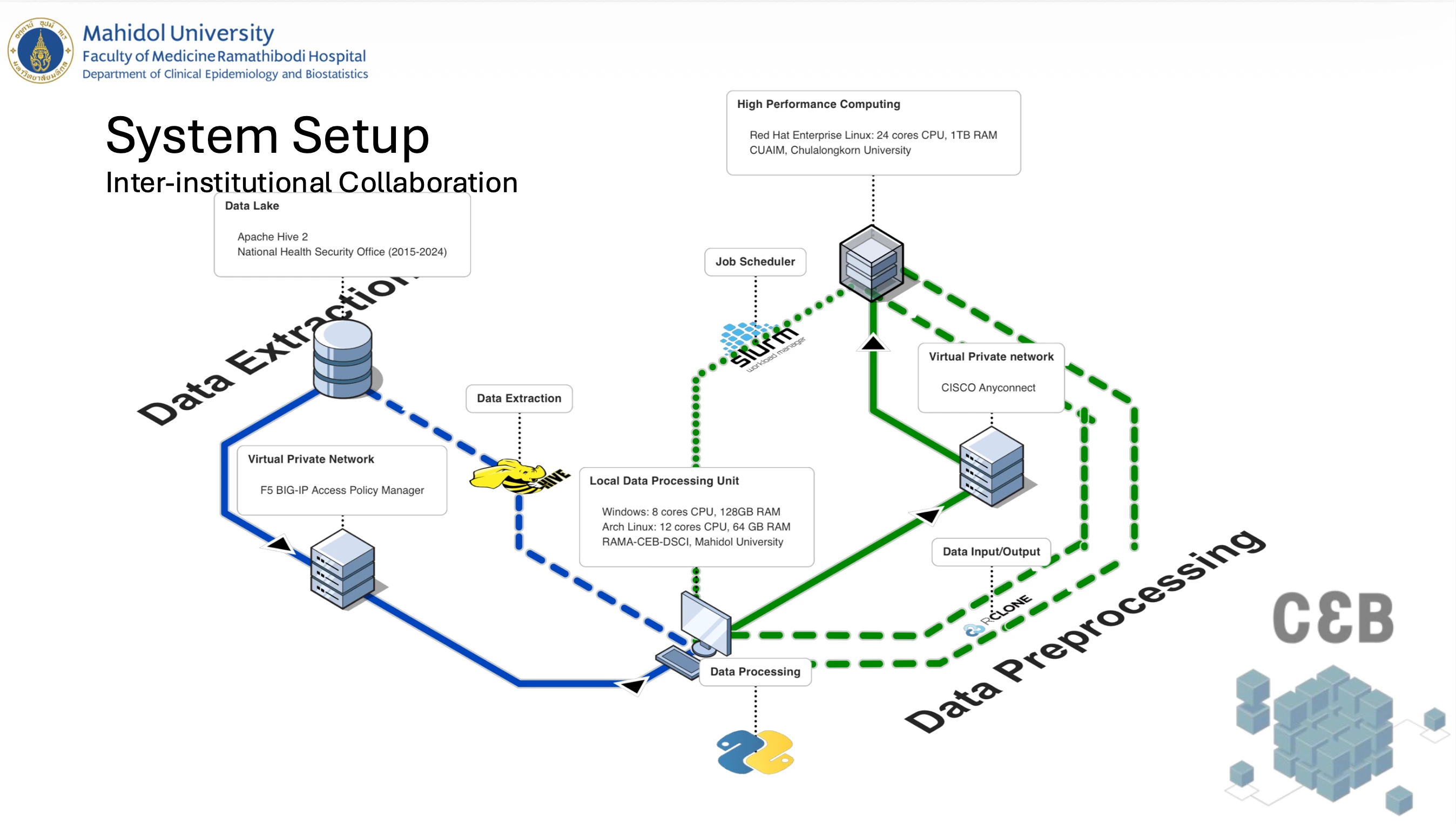
This is where inter-institutional collaboration became essential. Since the research question was proposed by the Dementia Association of Thailand, we had the opportunity to work with Dr Chavit Tunvirachaisakul at Chulalongkorn University. He was able to bring in high-performance computing (HPC) resources from the Center for Artificial Intelligence in Medicine (CU-AIM) at Chulalongkorn University. This led me to explore environments for distributed data processing. Beyond simply scaling up resources, this project required coordination across multiple institutions and computing infrastructures unlike single-institution datasets, where data processing can often be handled within a single controlled environment.
As a result, computational and governance constraints became tightly coupled and it required rethinking the entire data pipeline. This included adopting chunk-based processing, managing intermediate outputs, and designing workflows compatible with parallel execution. Operations such as large-scale joins and groupings became key bottlenecks, particularly during iterative cohort refinement. These constraints did not just affect infrastructure but they also influenced how certain variables were defined.
For example, patient residential information was not directly available and had to be inferred from the healthcare facility where coverage was registered. While this enables linkage to geographical units, it introduces a level of approximation when assigning environmental exposures. This is a common issue in real-world data research, where ideal variables are often not directly available and proxies must be used. In this case, it required careful consideration of the implications for exposure assessment and potential bias in the analysis.

Overall, the project highlighted a shift that is often understated in real-world data research: as datasets become larger and more comprehensive, the challenges shift from data availability to data reliability and computational feasibility. At national scale, data is abundant, but not necessarily consistent, complete, or directly usable. Methodological decisions are often shaped not only by analytical goals, but also by the structure of collaboration and the constraints of working across secure, distributed systems. The challenge is not simply to analyze the data, but to ensure that what is being analyzed remains both scalable and interpretable despite these constraints.
The slides can be found [here](/docs/2026_associations between PM2.5 Exposure and Head & Neck Cancer and Dementia in association with The Dementia Association of Thailand.pdf) and the subsection on dementia can be found [here](/docs/2026_associations between PM2.5 Exposure and Head & Neck Cancer and Dementia in association with The Dementia Association of Thailand_dementia_section.pdf).